如何使用Python爬虫 抓取论坛关键字出现频率!

![如何使用Python爬虫 抓取论坛关键字出现频率![Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696831595-983d26e50e334ce.jpg)
前言:
之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能。由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量。
这个项目总共分为两步:
1. 获取所有帖子的链接:
将最近一个月内的帖子链接保存到数组中
2. 从回帖中搜索演员名字:
从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字
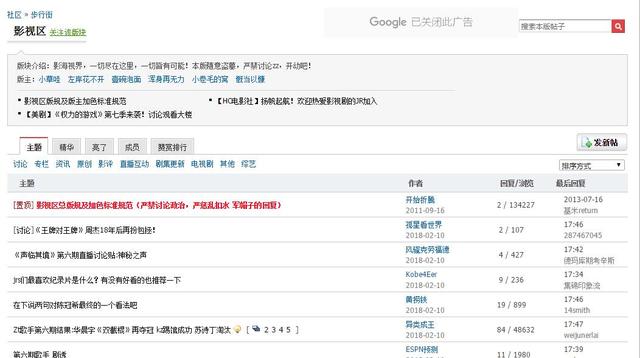
获取所有帖子的链接:
搜索的范围依然是以虎扑影视区为界限。虎扑影视区一天约5000个回帖,一月下来超过15万回帖,作为样本来说也不算小,有一定的参考价值。
完成这一步骤,主要分为以下几步:
1. 获取当前日期
2. 获取30天前的日期
3. 记录从第一页往后翻的所有发帖链接
1. 获取当前日期
这里我们用到了datetime模块。使用datetime.datetime.now(),可以获取当前的日期信息以及时间信息。在这个项目中,只需要用到日期信息就好。
2. 获取30天前的日期
用datetime模块的优点在于,它还有一个很好用的函数叫做timedelta,可以自行计算时间差。当给定参数days=30时,就会生成30天的时间差,再用当前日期减去delta,可以得到30天前的日期,将该日期保存为startday,即开始进行统计的日期。不然计算时间差需要自行考虑跨年闰年等因素,要通过一个较为复杂的函数才可以完成。
today = datetime.datetime.now()
delta = datetime.timedelta(days=30)
i = "%s" %(today - delta)
startday = i.split(" ")[0]
today = "%s" %today
today = today.split(" ")[0]
在获得开始日期与结束日期后,由于依然需要记录每一天每个人的讨论数,根据这两个日期生成两个字典,分别为actor1_dict与actor2_dict。字典以日期为key,以当日讨论数目作为value,便于每次新增查找记录时更新对应的value值。
strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftime days = (strptime(today, "%Y-%m-%d") - strptime(startday, "%Y-%m-%d")).days for i in range(days+1): temp = strftime(strptime(startday, "%Y-%m-%d") + datetime.timedelta(i), "%Y-%m-%d") actor1_dict[temp] = 0 actor2_dict[temp] = 0
3. 记录从第一页往后翻的所有发帖链接