PyCharm爬虫实例:使用Scrapy抓取网页特定内容、数据采集与数据预处理–biaobiao88

![PyCharm爬虫实例:使用Scrapy抓取网页特定内容、数据采集与数据预处理--biaobiao88[Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696934589-040c12a4ab98df8.jpg)
Scraoy入门实例一—Scrapy介绍与安装&PyCharm的安装&项目实战
一、Scrapy的安装
1.Scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说,网络抓取)所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
2.Scrapy安装
推荐使用Anaconda安装Scrapy
Anaconda是一个开源的包、环境管理神器,Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。从官网下载安装Anaconda(Individual Edition),根据自己的系统选择下载,进行安装,选择next继续安装,Install for选项选Just for me,选择安装位置后,静待完成安装。
装好之后打开命令行,输入conda install scrapy,然后根据提示按Y,就会将Scrapy及其依赖的包全部下载下来,这样就完成了安装。
注意:在使用命令行安装scrapy包时,会出现下载超时的问题,即下载失败,我们可以通过修改其的镜像文件,以此来提高下载scrapy包的速度。可参考博客:https://blog.csdn.net/zhoulizhu/article/details/78809459
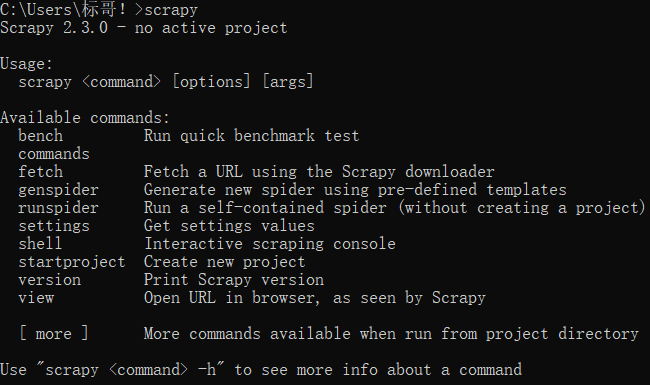
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy回车,如果显示如下界面就证明安装成功:
二、PyCharm的安装
1.PyCharm介绍
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
2.PyCharm安装
进入PyCharm的官网,直接点击DownLoad进行下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:https://www.jb51.net/article/161175.htm
三、Scrapy抓取豆瓣项目实战
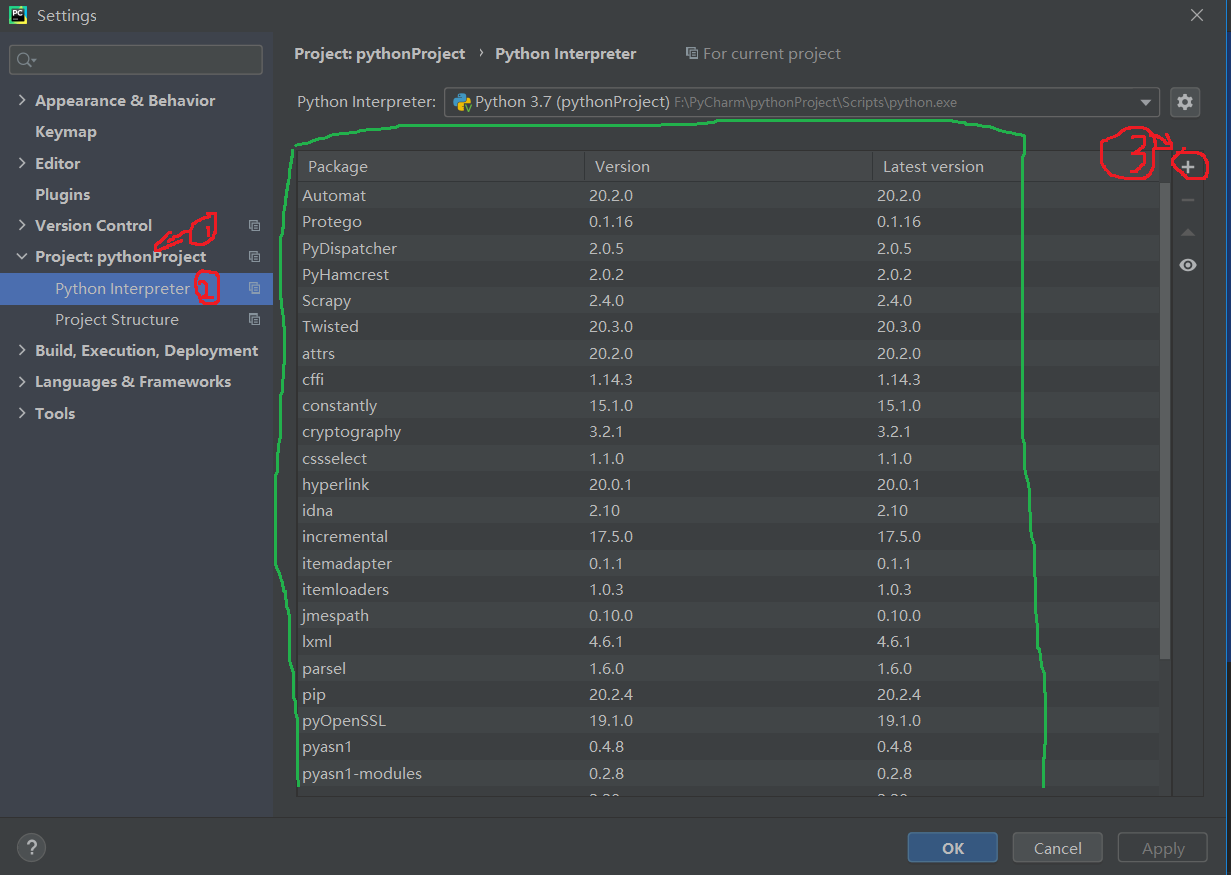
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings…),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可
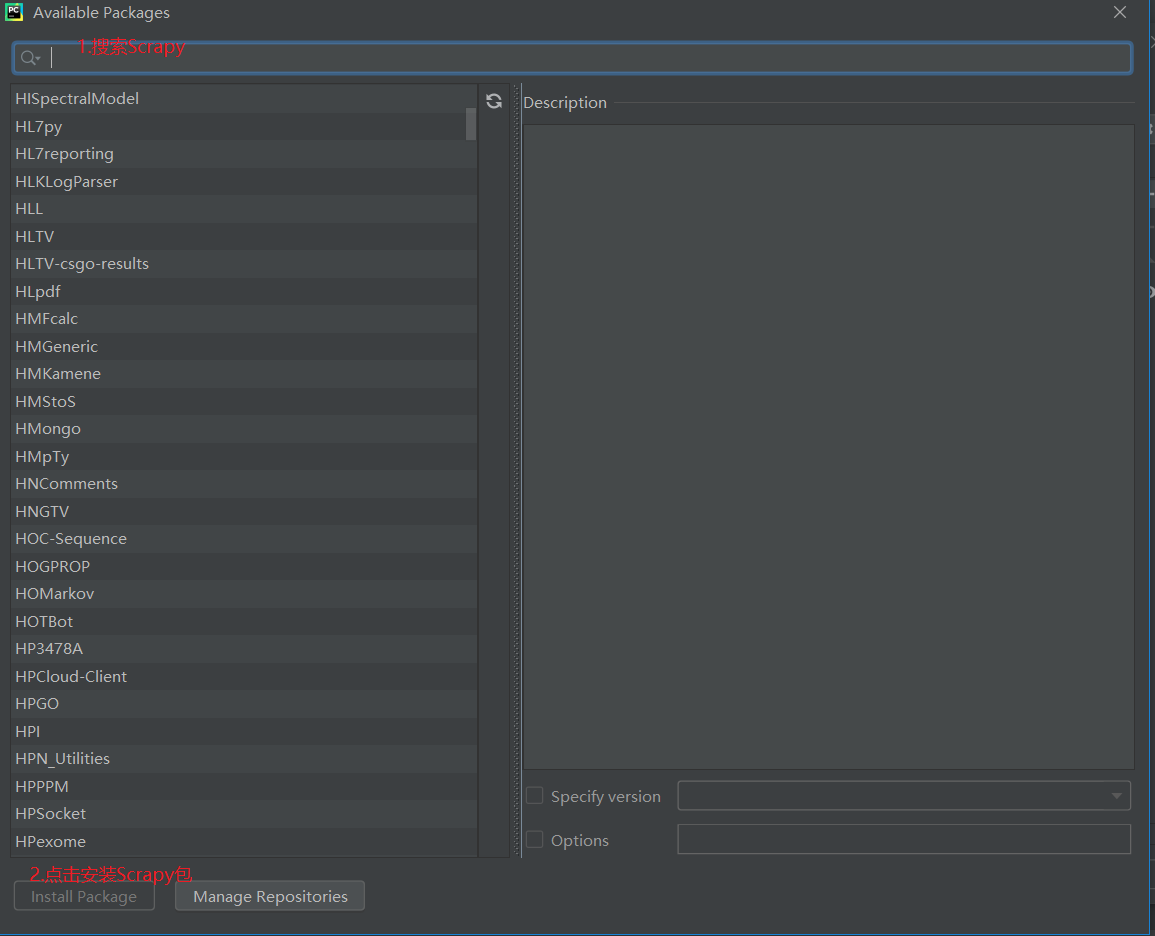
如果没有Scrapy包的话,点击“+” ,搜索Scrapy包,点击Install Package 进行安装
等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了

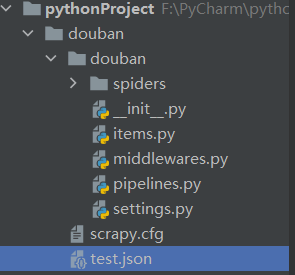
输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject
接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider movie.douban.com 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
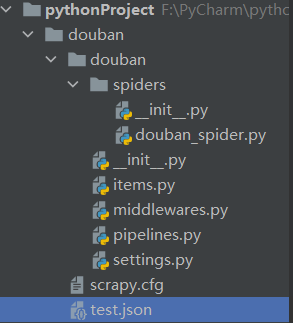
2.明确目标
我们要练习的网站为:https://movie.douban.com/top250
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
