:爬取(谷歌/百度/搜狗)的搜索结果

![【Python爬虫】:爬取(谷歌/百度/搜狗)的搜索结果[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696831632-288733255b587c4.jpg)
步骤如下:
1.首先导入爬虫的package:requests
2.使用UA 伪装进行反反爬虫,将爬虫伪装成一个浏览器进行上网
3.通过寻找,找到到谷歌搜索时请求的url。
假设我们在谷歌浏览器当中输入:不知道
我们可以得到请求结果的网址如下:
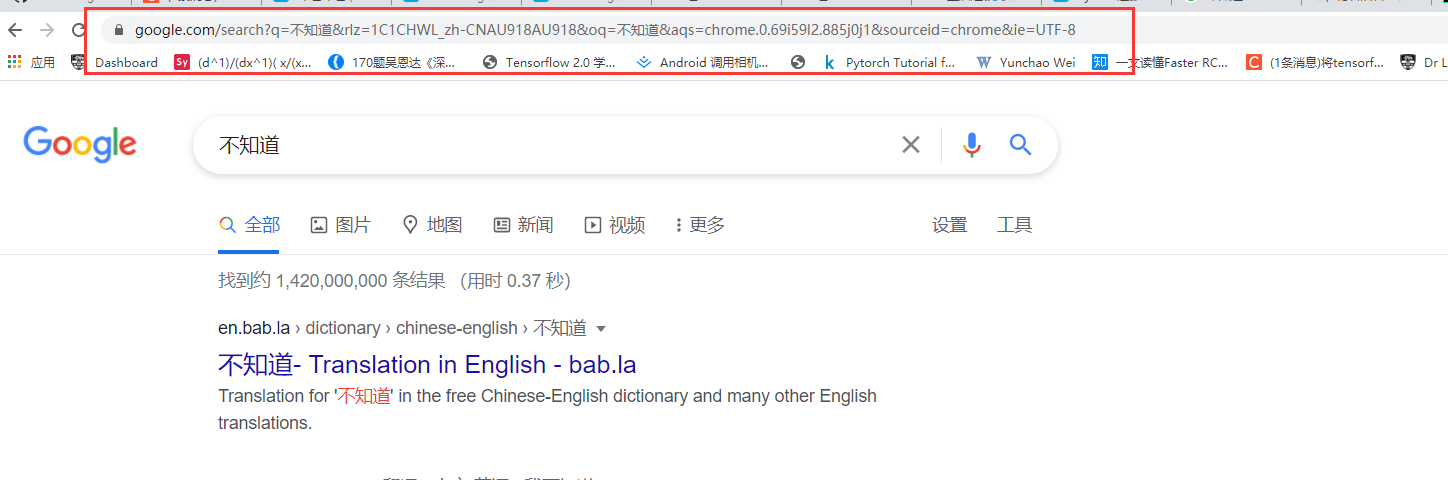
也就是:
https://www.google.com/search?q=%E4%B8%8D%E7%9F%A5%E9%81%93&rlz=1C1CHWL_zh-CNAU918AU918&oq=%E4%B8%8D%E7%9F%A5%E9%81%93&aqs=chrome.0.69i59l2.885j0j1&sourceid=chrome&ie=UTF-
